HTML5 的FileReader API 可以让客户端浏览器对用户本地文件进行读取,这样就不再需要上传文件由服务器进行读取了,这大大减轻了服务器的负担,也节省了上传文件所需要的时间。不过在实践中我发现用FileReader.readAsText()可以轻易地处理一个 300k 的日志文件,但当日志文件有 1G、甚至 2G 那么大,浏览器就会崩溃。这是因为readAsText()会一下子把目标文件加载至内存,导致内存超出上限。所以如果 Web 应用常常需要处理大文件时,我们应该使用FileReader.readAsArrayBuffer()来一块一块读取文件。
测试场景
我们的场景很简单,就是使用 JavaScript 来获取某个 IIS 日志的时间范围
样例 IIS 日志:
#Software: Microsoft Internet Information Services 10.0
#Version: 1.0
#Date: 2016-08-18 06:53:55
#Fields: date time s-ip cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Referer) sc-status sc-substatus sc-win32-status time-taken
2016-08-18 06:53:55 ::1 GET / - 80 - ::1 Mozilla/5.0+(Windows+NT+10.0;+WOW64;+Trident/7.0;+rv:11.0)+like+Gecko - 200 0 0 476
2016-08-18 06:53:55 ::1 GET /iisstart.png - 80 - ::1 Mozilla/5.0+(Windows+NT+10.0;+WOW64;+Trident/7.0;+rv:11.0)+like+Gecko http://localhost/ 200 0 0 3
2016-08-18 08:45:34 10.172.19.198 GET /test/pac/wpad.dat - 80 - 10.157.21.235 Mozilla/5.0+(Windows+NT+6.1;+Win64;+x64;+Trident/7.0;+rv:11.0)+like+Gecko - 404 3 50 265
2016-08-18 08:46:44 10.172.19.198 GET /test/pac/wpad.dat - 80 - 10.157.21.235 Mozilla/5.0+(Windows+NT+6.1;+Win64;+x64;+Trident/7.0;+rv:11.0)+like+Gecko - 200 0 0 6
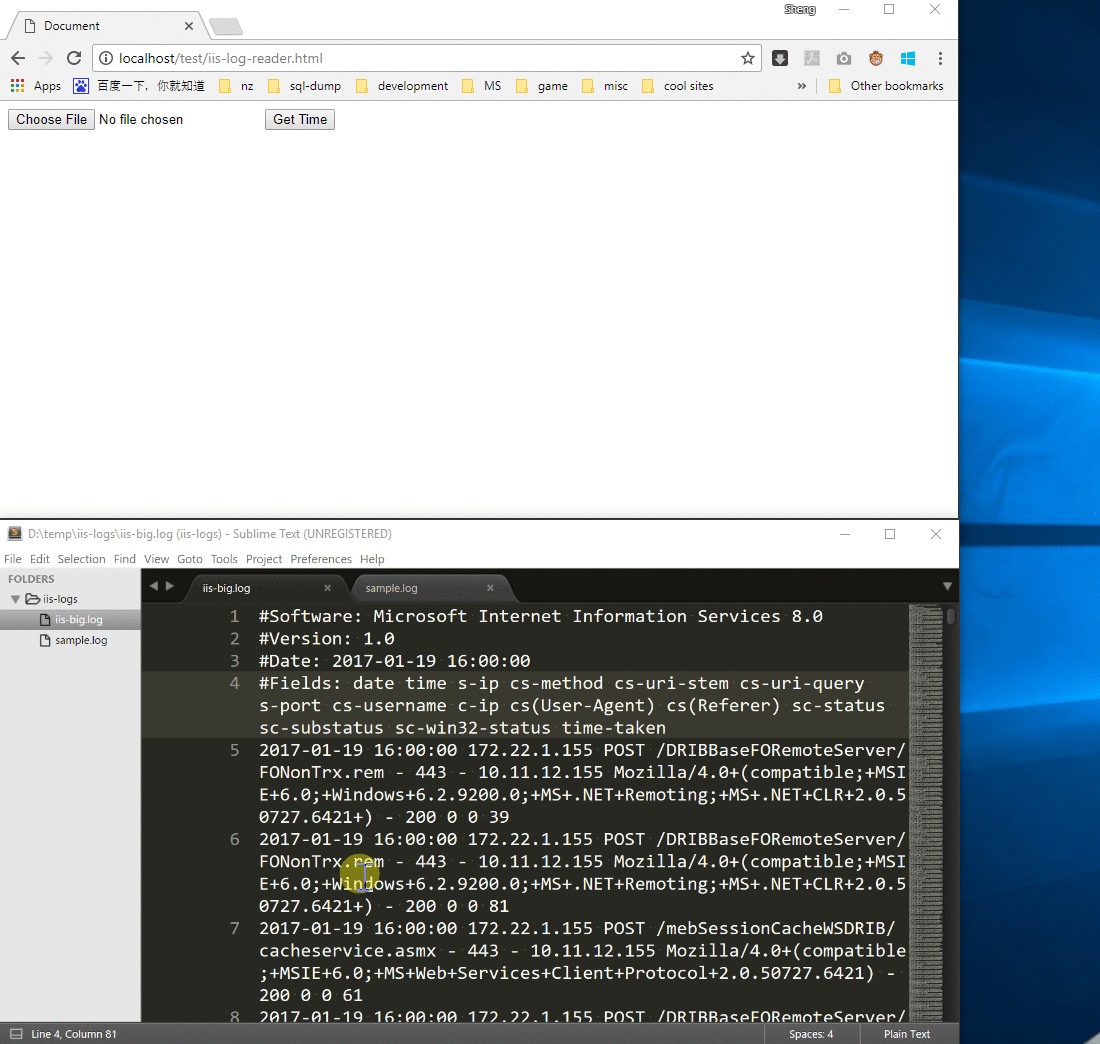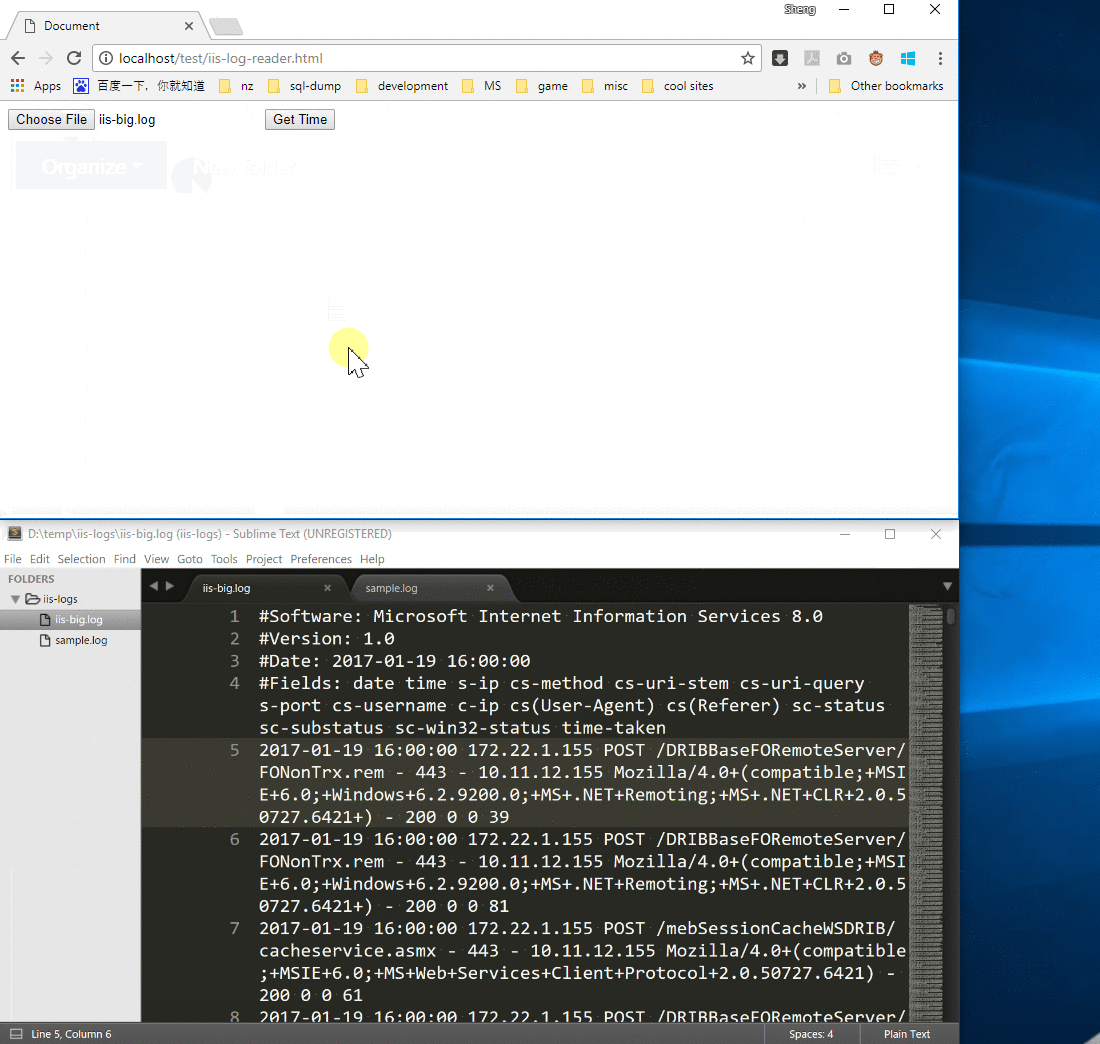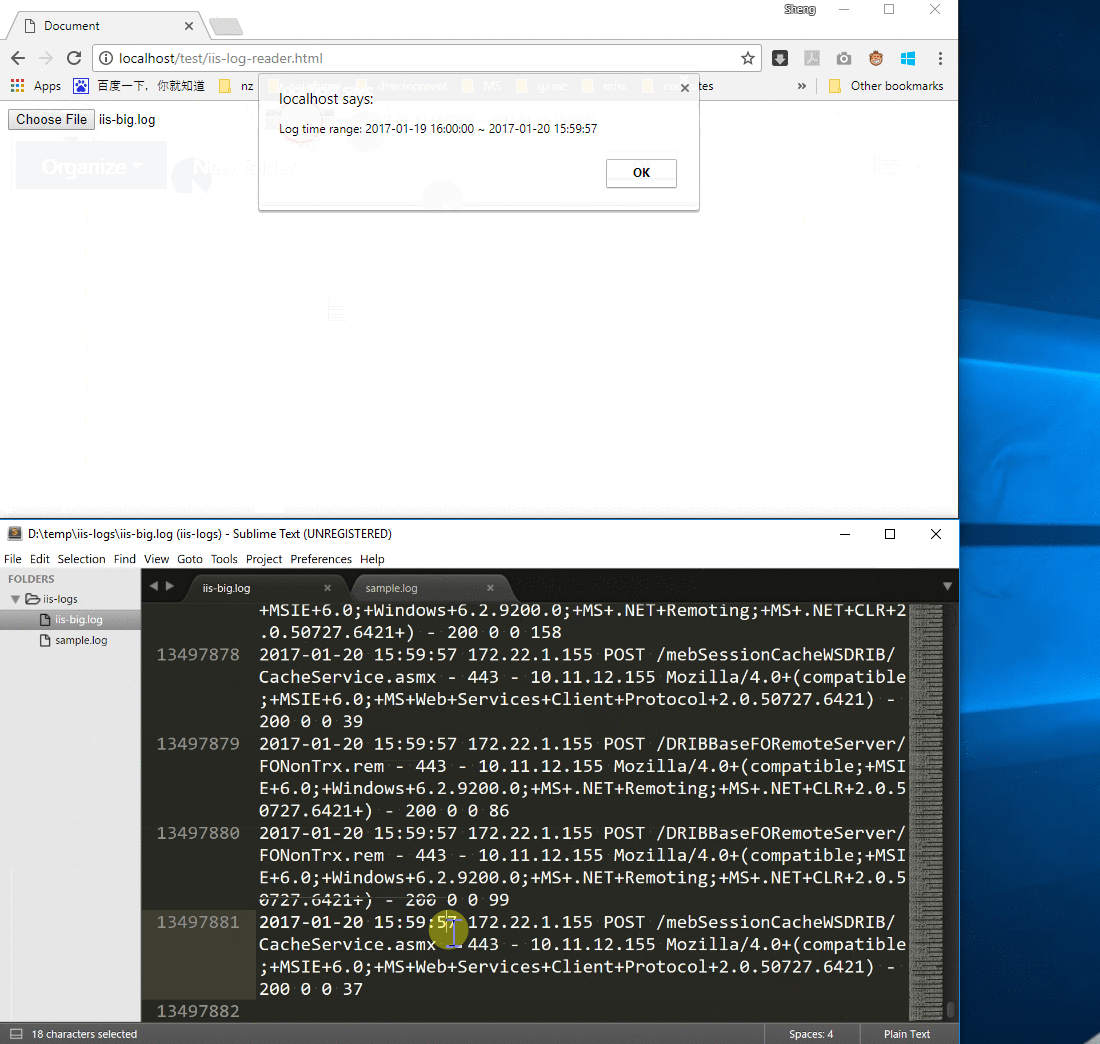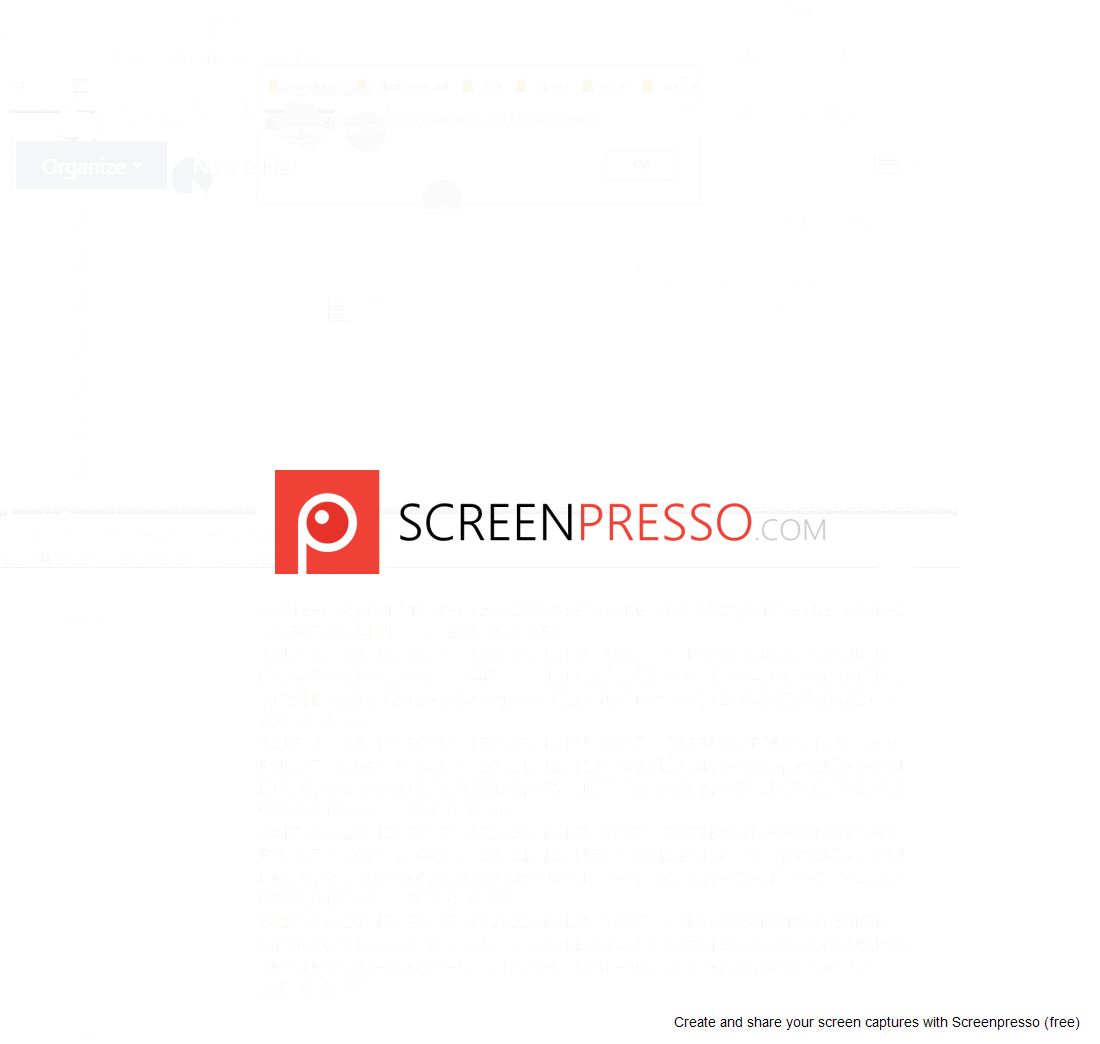
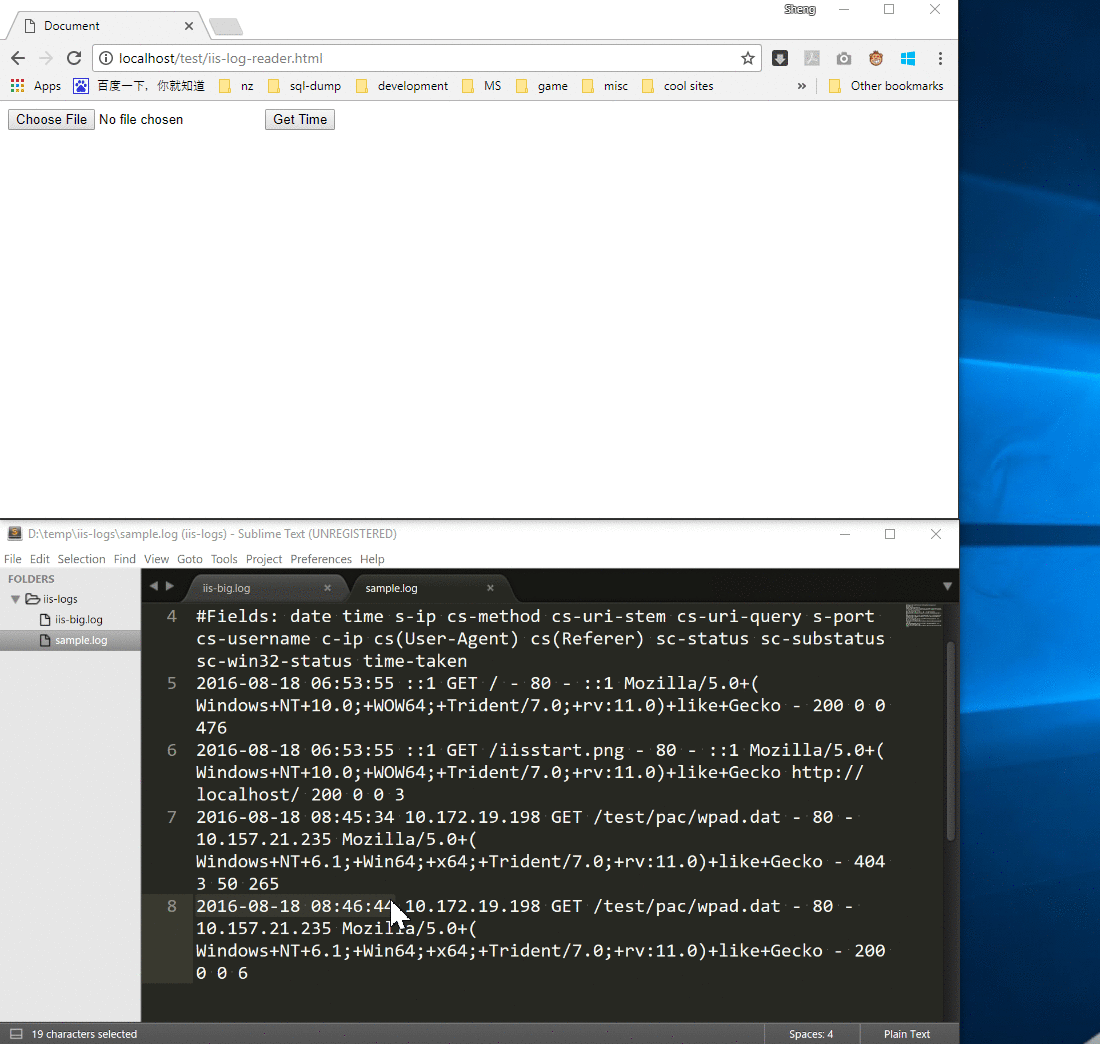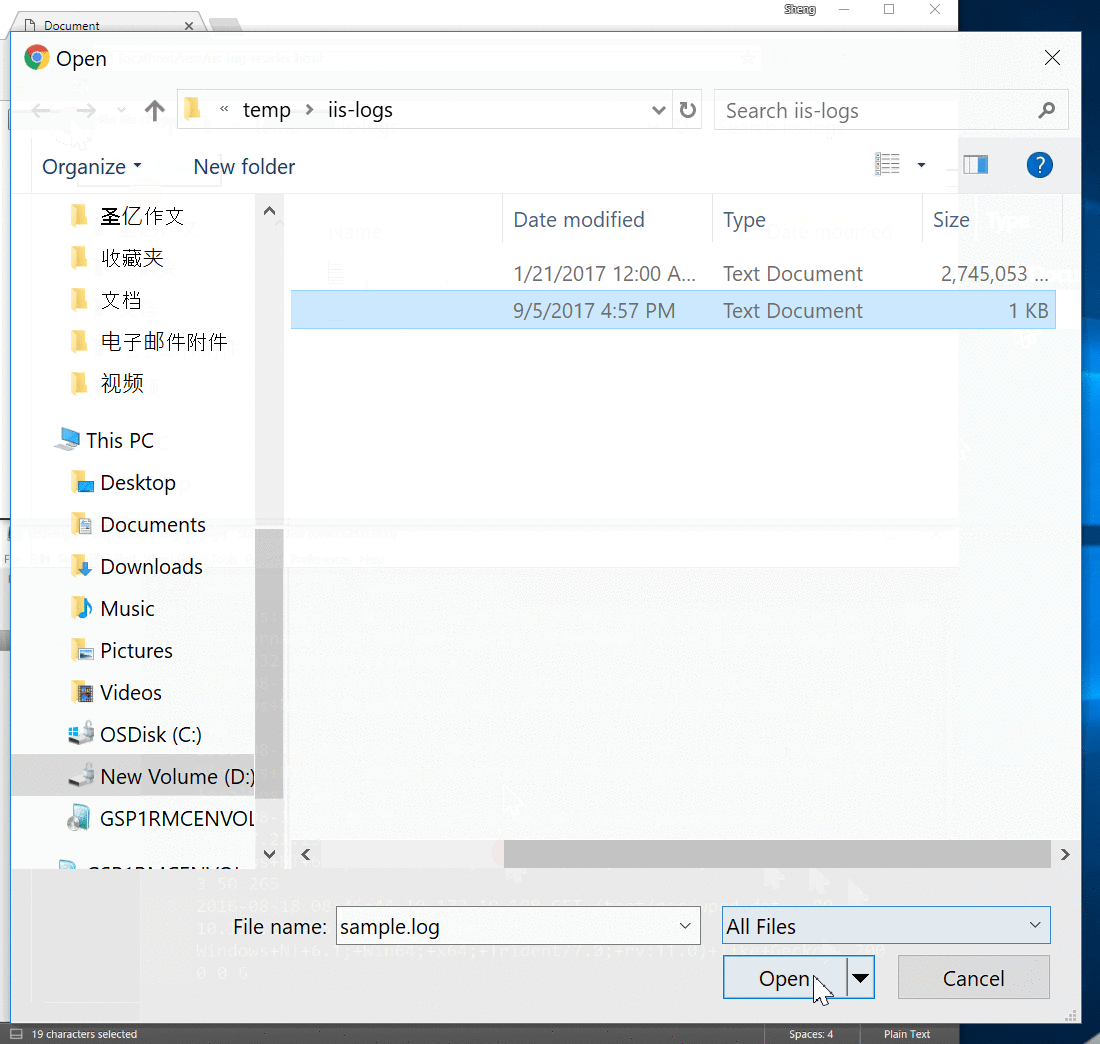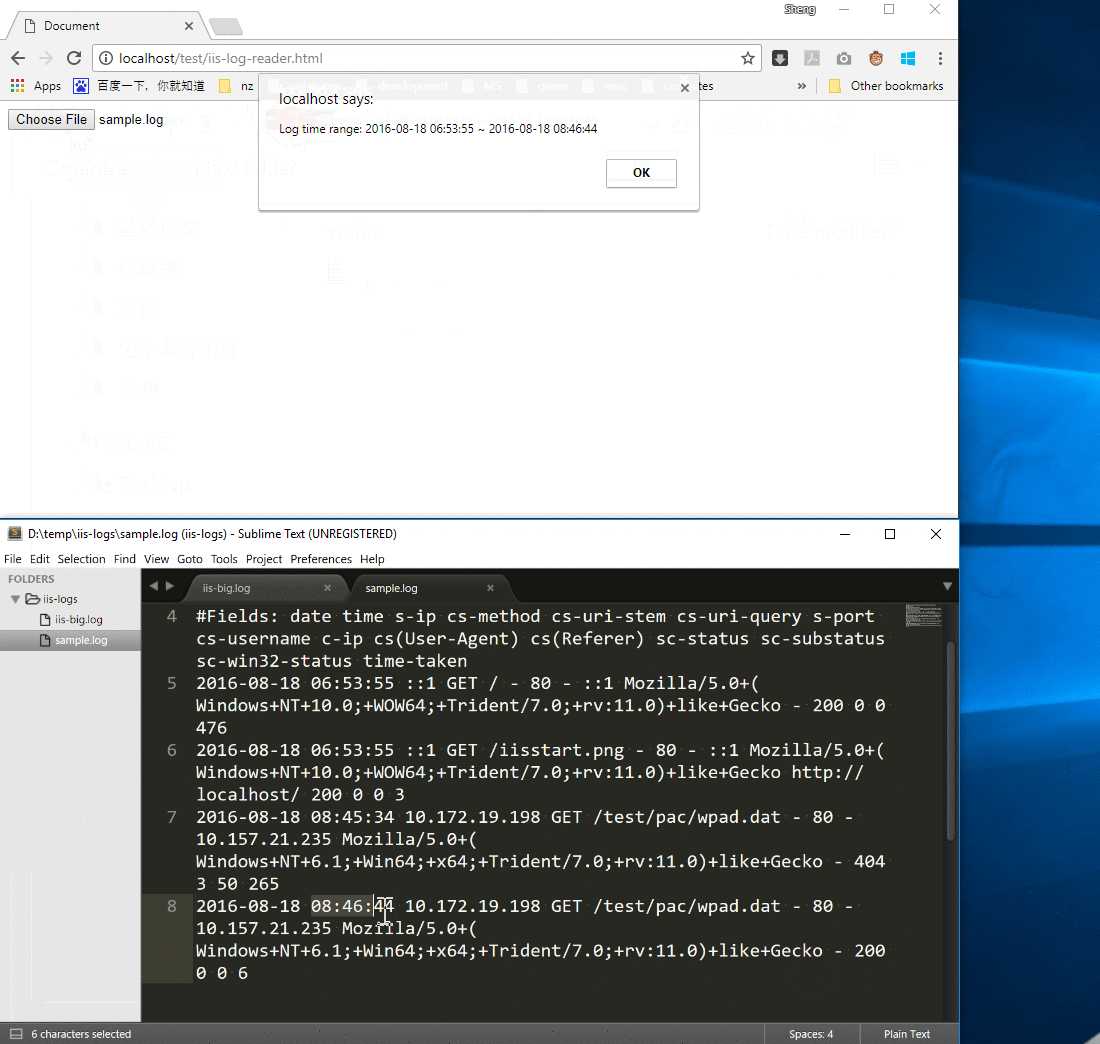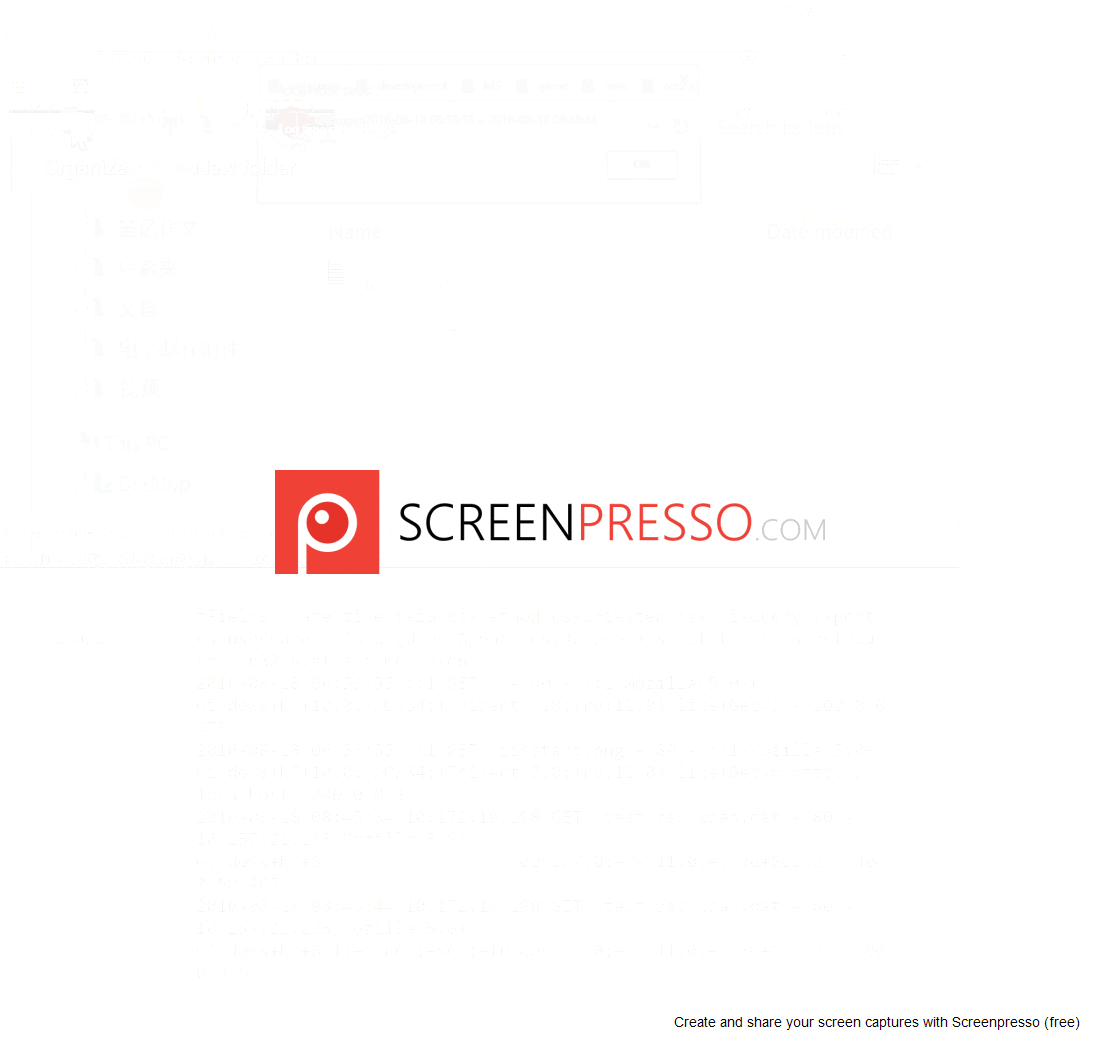
我们的目标就是获取该段日志的时间范围:
- 开始时间:2016-08-18 06:53:55
- 结束时间:2016-08-18 08:46:44
使用readAsText()的实现
使用readAsText()实现是比较简单的,得到整个文件的字符串后,从头获取每一行的前 19 个字符,判断是否满足日期的格式,如果满足那么这 19 个字符就是开始时间,同理从尾部遍历每一行来获取结束时间,代码如下:
<input type="file" id="file" />
<button id="get-time">Get Time</button>
<script>
document.getElementById('get-time').onclick = function () {
let file = document.getElementById('file').files[0];
let fr = new FileReader();
fr.onload = function (e) {
let startTime = getTime(e.target.result, false);
let endTime = getTime(e.target.result, true);
alert(`Log time range: ${startTime} ~ ${endTime}`);
};
fr.readAsText(file);
};
function getTime(text, reverse) {
let timeReg = /\d{4}\-\d{2}\-\d{2} \d{2}:\d{2}:\d{2}/;
for (
let i = reverse ? text.length - 1 : 0;
reverse ? i > -1 : i < text.length;
reverse ? i-- : i++
) {
if (text[i].charCodeAt() === 10) {
let snippet = text.substr(i + 1, 19);
if (timeReg.exec(snippet)) {
return snippet;
}
}
}
}
</script>
样例 IIS 日志(大小:1k)的运行结果符合我们的预期。
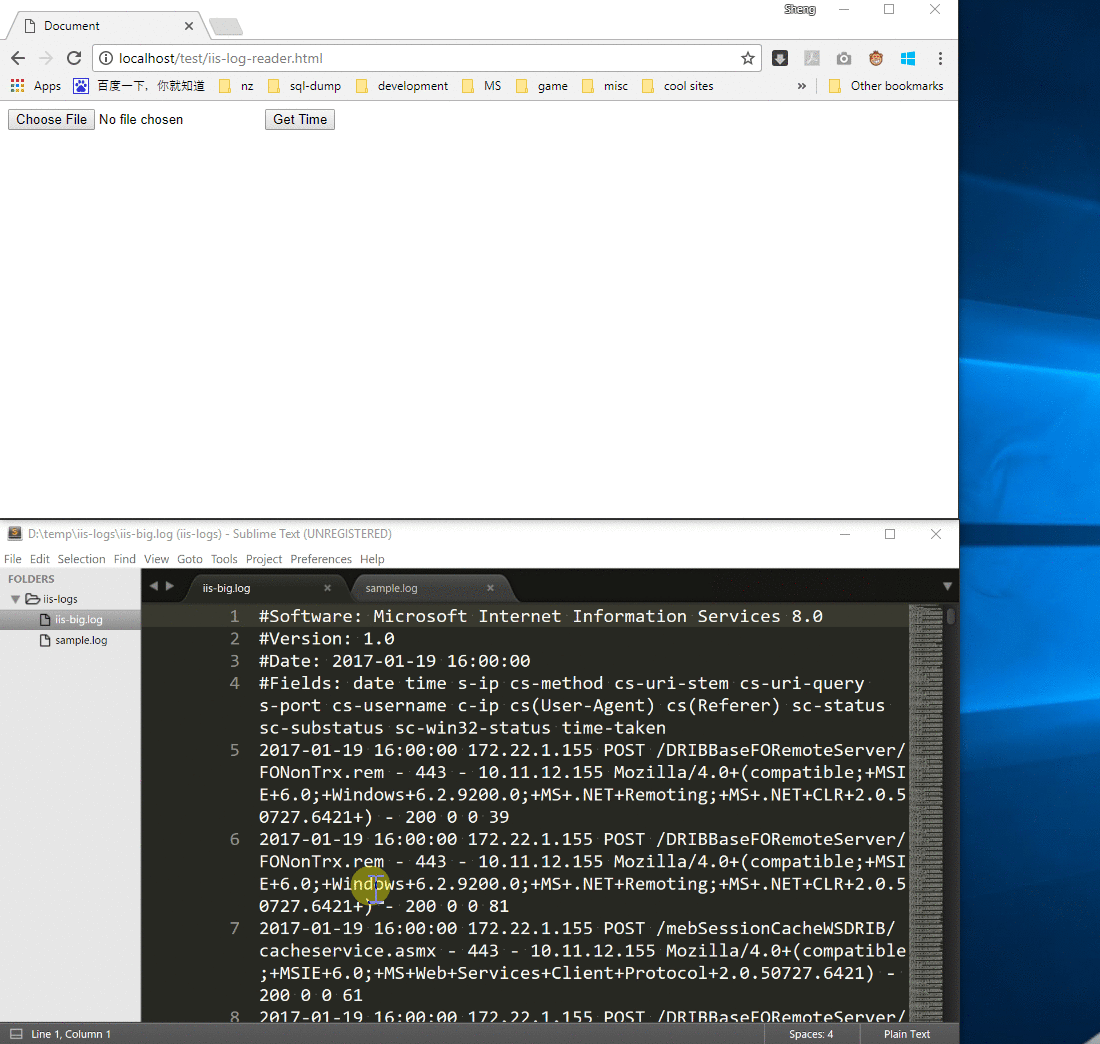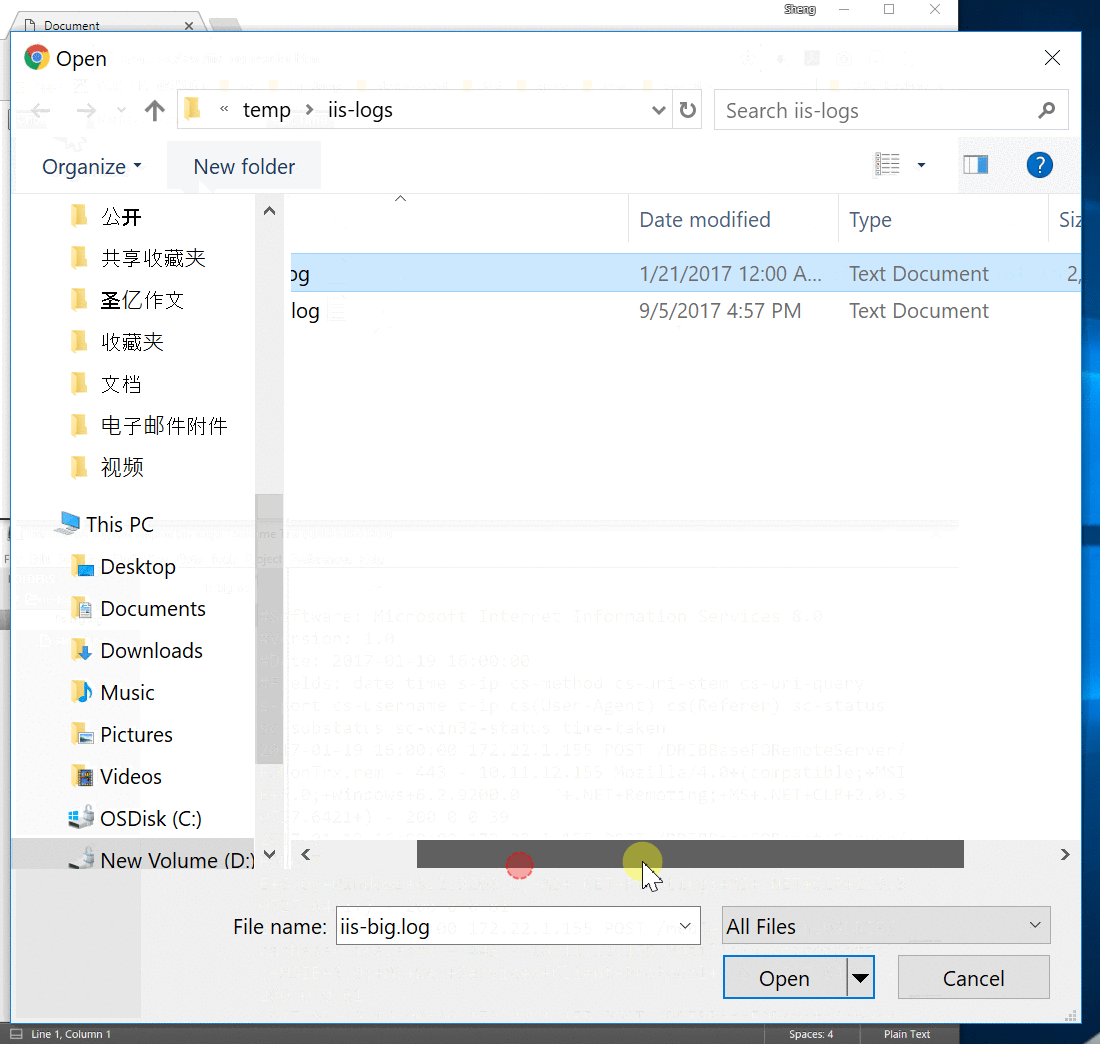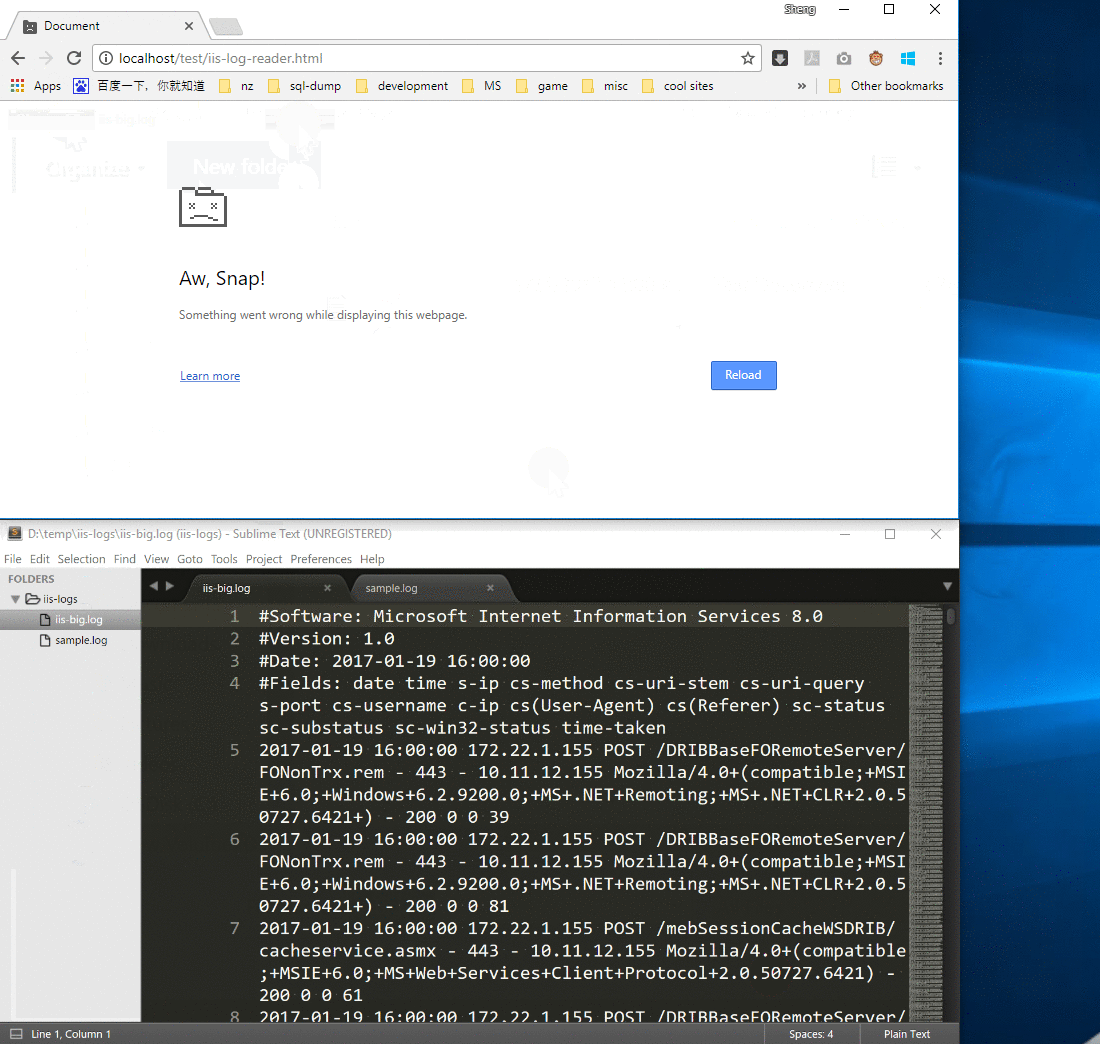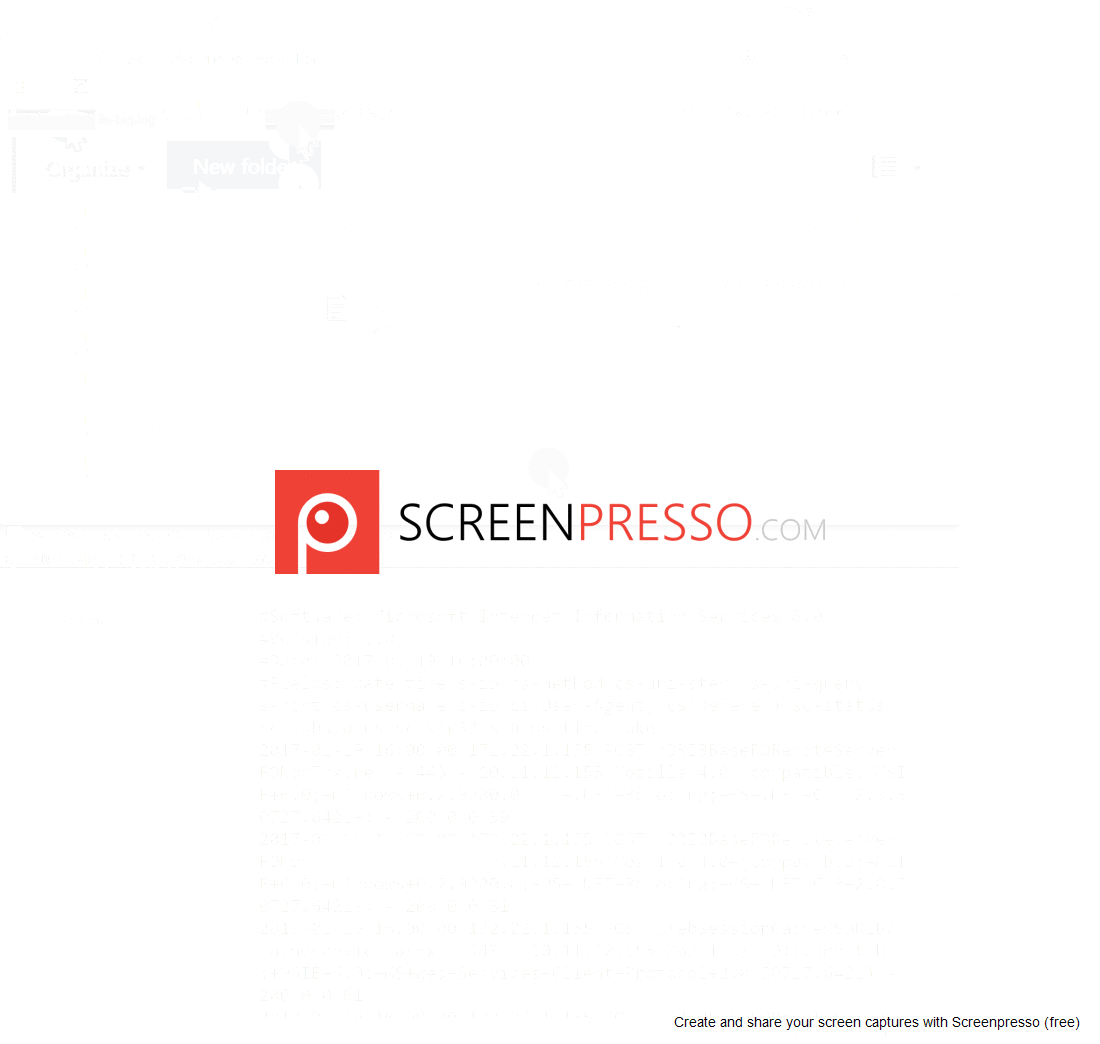
可是一旦我们选择了一个较大的 IIS 日志(大小:2G),浏览器就崩溃了。原因就是readAsText()会先把整个文件加载到内存中,那么如果文件太大,内存就不够用了,浏览器进程就会崩溃。
使用readAsArrayBuffer()的实现
由于 JavaScript 中的File对象继承自Blob,所以我们完全可以用Blob.slice()方法将文件切成小块来处理,大致思路是:
- 先取文件的前 10k 内容,转换成文本
- 从头获取每一行的前 19 个字符,判断是否满足日期的格式,如果满足那么这 19 个字符就是开始时间
- 再取文件尾部的 10k 内容,转换成文本
- 同理从尾部内容遍历每一行来获取结束时间
代码如下:
<input type="file" id="file" />
<button id="get-time">Get Time</button>
<script>
document.getElementById('get-time').onclick = function () {
let file = document.getElementById('file').files[0];
let fr = new FileReader();
let CHUNK_SIZE = 10 * 1024;
let startTime, endTime;
let reverse = false;
fr.onload = function () {
let buffer = new Uint8Array(fr.result);
let timeReg = /\d{4}\-\d{2}\-\d{2} \d{2}:\d{2}:\d{2}/;
for (
let i = reverse ? buffer.length - 1 : 0;
reverse ? i > -1 : i < buffer.length;
reverse ? i-- : i++
) {
if (buffer[i] === 10) {
let snippet = new TextDecoder('utf-8').decode(
buffer.slice(i + 1, i + 20)
);
if (timeReg.exec(snippet)) {
if (!reverse) {
startTime = snippet;
reverse = true;
seek();
} else {
endTime = snippet;
alert(`Log time range: ${startTime} ~ ${endTime}`);
}
break;
}
}
}
};
seek();
function seek() {
let start = reverse ? file.size - CHUNK_SIZE : 0;
let end = reverse ? file.size : CHUNK_SIZE;
let slice = file.slice(start, end);
fr.readAsArrayBuffer(slice);
}
};
</script>
使用了readAsArrayBuffer()后,即使是 2G 多的 IIS 日志,我们也能在很短的时间内获得我们想要的结果。